ElasticSearch 基础
2019-04-02 刚子 tools es- content
总结ElasticSearch的基础知识点
一、简易教程
概念
1. 下载安装
下载安装文件到/opt/elasticsearch目录下面并解压
>cd /opt/elasticsearch
>tar -zxvf elasticsearch-5.5.3.tar.gz
2. 启动并访问
>cd /opt/elasticsearch/elasticsearch-5.5.3
>./bin/elasticsearch
##./bin/elasticsearch -d 后台启动
root账户启动会报错:can not run elasticsearch as root,创建独立的用户来启动
>groupadd esgroup
>useradd esuser -g esgroup
>passwd esuser
>chown -R esuser:esgroup elasticsearch/
root用户关闭防火墙
>vi /etc/selinux/config
SELINUX=disabled
>systemctl stop firewalld.service
>systemctl disable firewalld.service
>setenforce 0
>getenforce 0
es配置可以使用ip访问
>vi config/elasticsearch.yml
network.host: 192.168.237.129 #或者0.0.0.0允许所有人访问
>su root
>vim /etc/security/limits.conf
esuser hard nofile 65536
esuser soft nofile 65536
>vi /etc/sysctl.conf
vm.max_map_count=655360
>sysctl -p
3. 创建、删除索引
curl -X PUT 'http://localhost:9200/weather'
curl -X DELETE 'http://localhost:9200/weather'
一个索引可以有多个分片来完成存储,但是主分片的数量是在索引创建时就指定好的,且无法修改,所以尽量不要只为数据存储建立一个索引,否则后面数据膨胀时就无法调整了。笔者的建议是对于同一类型的数据,根据时间来分拆索引,比如一周建一个索引,具体取决于数据增长速度。
4. 添加文档
curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'
5. 搜索所有文档
http://localhost:9200/_search # 搜索所有索引和所有类型
http://localhost:9200/movies/_search # 在电影索引中搜索所有类型
http://localhost:9200/movies/movie/_search # 在电影索引中显式搜索电影类型的文档
6. 安装中文分词插件
>./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.3/elasticsearch-analysis-ik-5.5.3.zip
7. 创建索引,并对文档字段进行中文分词
curl -X PUT 'http://localhost:9200/accounts' -d '
{
"mappings": {
"person": {
"properties": {
"user": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}'
curl -XPUT "http://localhost:9200/accounts/person/1" -d'
{
"user": "zhangsan",
"title": "管理员",
"desc": "我是系统管理员"
}'
curl -XPUT "http://localhost:9200/accounts/person/2" -d'
{
"user": "lisi",
"title": "组长",
"desc": "我是组长"
}'
8. 搜索指定字段
curl 'http://localhost:9200/accounts/person/_search' -d '
{
"query" : { "match" : { "desc" : "系统" }},
"from": 1,
"size": 1
}'
# from指定分页起始位置
# size表示每页几条数据
9. 查询索引信息
# 列出所有的索引
curl localhost:9200/_cat/indices?v
# 查看索引的文档数量
curl localhost:9200/_cat/count/accounts?v
# 查看文档字段信息
curl localhost:9200/accounts/person/_mapping
# 删除索引
curl -X DELETE localhost:9200/accounts
二、查询DSL
- 添加雇员索引文档
curl -X PUT "localhost:9200/megacorp/employee/1" -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
'
- 创建文档,非更新
PUT /website/blog/123?op_type=create
# or
PUT /website/blog/123/_create
- 检查文档是否存在
curl -i -XHEAD http://localhost:9200/website/blog/123
- QueryString搜索
curl -X GET "localhost:9200/megacorp/employee/_search?q=last_name:Smith"
- 查询表达式(DSL:domain-specific language)搜索指定字段
curl -X GET "localhost:9200/megacorp/employee/_search" -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
'
- 过滤器–对查询结果进行进一步过滤
# 搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的
curl -X GET "localhost:9200/megacorp/employee/_search" -H 'Content-Type: application/json' -d'
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
'
- 全文搜索
curl -X GET "localhost:9200/megacorp/employee/_search" -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
'
- 短语搜索–精确匹配内容中出现短语的文档
curl -X GET "localhost:9200/megacorp/employee/_search" -H 'Content-Type: application/json' -d'
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
'
- 高亮搜索
curl -X GET "localhost:9200/megacorp/employee/_search" -H 'Content-Type: application/json' -d'
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
'
更多高亮设置参考官方文档
- 数据分析–聚合、汇总
- 通过版本号更新数据
curl -X PUT "localhost:9200/website/blog/1?version=1" -H 'Content-Type: application/json' -d'
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
'
更多请参考乐观并发控制
案例
PUT _template/coupon_search_template
{
"order":10,
"index_patterns":[
"coupon_search_*"
],
"settings":{
"index.number_of_replicas":"1",
"index.number_of_shards":"2",
"index.refresh_interval":"1s",
"index.search.slowlog.level":"info",
"index.search.slowlog.threshold.fetch.debug":"100ms",
"index.search.slowlog.threshold.fetch.info":"500ms",
"index.search.slowlog.threshold.fetch.trace":"50ms",
"index.search.slowlog.threshold.fetch.warn":"1s",
"index.search.slowlog.threshold.query.debug":"100ms",
"index.search.slowlog.threshold.query.info":"500ms",
"index.search.slowlog.threshold.query.trace":"50ms",
"index.search.slowlog.threshold.query.warn":"1s",
"index.unassigned.node_left.delayed_timeout":"1d"
},
"mappings":{
"dynamic":false,
"properties":{
"ztoUserId":{
"type":"keyword"
},
"couponSn":{
"type":"keyword"
},
"mobile":{
"type":"keyword"
},
"orderId":{
"type":"keyword"
},
"receiveTime":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss",
"locale":"zh_CN"
}
}
},
"aliases":{
"coupon_alias":{}
}
}
PUT coupon_search_all
POST /coupon_search_all/_doc
{
"ztoUserId":"123456",
"couponSn":"CS0001",
"mobile":"13057271932",
"orderId":"O0001",
"receiveTime":"2020-01-01 08:00:00"
}
GET /coupon_search_all/_search
GET /coupon_search_all/_search
{
"query": {
"match": {
"mobile": "13057271932"
}
}
}
GET /coupon_search_all/_search
{
"query": {
"wildcard": {
"mobile": {
"value": "1305727*"
}
}
},
"sort": [
{
"receiveTime": {
"order": "desc"
}
}
]
}
GET /coupon_search_all/_search
{
"query": {
"prefix": {
"mobile": {
"value": "13057"
}
}
},
"sort": [
{
"receiveTime": {
"order": "desc"
}
}
]
}
POST /coupon_search_all/_update/QAivYXcB89UkBtu30_Fl
{
"doc":{
"mobile":"13057271933"
}
}
字段类型
date
#给example索引新增一个birthday字段,类型为date, 格式可以是yyyy-MM-dd 或 yyyy-MM-dd HH:mm:ss
#添加日期类型的映射
PUT test_label_supplier/docs/_mapping
{
"properties": {
"birthday": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
"ignore_malformed": false,
"null_value": null
}
}
}
三、Kibana
下载安装
从下载地址下载到/opt/elasticsearch目录下并解压
tar -zxvf kibana-5.5.3-linux-x86_64.tar.gz
设置任何人都可以访问
>vim config/kibana.yml
server.host: "0.0.0.0"
启动并访问
>./bin/kibana
>./bin/kibana & #后面添加&代表后台启动,shell窗口执行exit命令后kibana会一直后台启动
查询语法
四、中文分词
英文分词示例
PUT test/doc/1
{
"msg":"Eating an apple a day keeps doctor away"
}
# 使用单词eat无法搜索到包含eating的内容
POST test/_search
{
"query":{
"match":{
"msg":"eat"
}
}
}
# 分析一下字段的分词规则,发现默认的standard分词器没有把eating切分为eat
POST test/_analyze
{
"field": "msg",
"text": "Eating an apple a day keeps doctor away"
}
# 新加一个字段,指定写分词器为english,写分词器一经指定就不能修改,如果修改的话只能重建索引
PUT test/_mapping/doc
{
"properties": {
"msg_english":{
"type":"text",
"analyzer": "english"
}
}
}
POST test/doc/2
{
"msg":"Eating an apple a day keeps doctor away",
"msg_english":"Eating an apple a day keeps doctor away"
}
# 这时候再分析一下字段,发现eat已经可以匹配eating
POST test/_analyze
{
"field": "msg_english",
"text": "Eating an apple a day keeps doctor away"
}
# 尝试搜索一下看看,搜索分词器不指定的话默认与写分词器一致,一般来讲不需要特别指定搜索分词器
POST test/_search
{
"query":{
"match":{
"msg_english":{
"query": "eat"
}
}
}
}
# standard分词器添加三个过滤器之后效果与english分词器一样,stemmer指的是词干提取
POST _analyze
{
"char_filter": [],
"tokenizer": "standard",
"filter": [
"stop",
"lowercase",
"stemmer"
],
"text": "Eating an apple a day keeps doctor away"
}
安装使用中文分词插件ik
>./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.3/elasticsearch-analysis-ik-5.5.3.zip
- 指定索引中文档的分词器的类型为ik
# 试一下IK的分词器分词效果
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我爱北京天安门"
}
# 或者
POST _analyze
{
"char_filter": [],
"tokenizer": "ik_max_word",
"filter": [],
"text": "我爱北京天安门"
}
# 设置索引文档字段的分词器,注意只能设置一次,否则只能重新创建索引
PUT /test1
{
"mappings": {
"person": {
"properties": {
"user": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
PUT test1/person/1
{
"user":"用户1",
"title":"标题",
"desc":"注意只能设置一次,否则只能重新创建索引"
}
GET test1/person/_search
{
"query": {
"match": {
"desc": "注意"
}
}
}
# 查看字段分词器用的是哪个
GET test1/person/_mapping
自定义静态词库文件
# 创建自定义词库文件my.dic
>/opt/elasticsearch/elasticsearch-5.5.3/config/analysis-ik
>vim my.dic
我爱北京天安门
#修改ik配置文件,指定词库文件
>vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
# 重启ES试一下分词效果
POST _analyze
{
"char_filter": [],
"tokenizer": "ik_max_word",
"filter": [],
"text": "我爱北京天安门"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我爱北京天安门"
}
自定义动态词库文件
# 设置动态词库url地址
>cd /opt/tomcat/apache-tomcat-8.5.37/webapps/ROOT
>vim my.dic
我爱
#修改ik配置文件,指定词库文件
>vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.255.131:8080/my.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
# 重启ES试一下分词效果
POST _analyze
{
"char_filter": [],
"tokenizer": "ik_max_word",
"filter": [],
"text": "我爱北京天安门"
}
# 修改自定义远程词库之后会有最多1分钟生效时间
维护ik自定义词库到数据库(未经实验)
//提供head请求服务,让ES隔一分钟调用一次,判断词库是否发生变化
@RequestMapping(value="/es/getCustomDic",method=RequestMethod.HEAD)
public void getCustomDic(HttpServletRequest request,HttpServletResponse response) throws Exception{
String latest_ETags=getLatest_ETags();
String old_ETags=request.getHeader("If-None-Match");
if(latest_ETags.equals("")||!latest_ETags.equals(old_ETags)){
refreshETags();
response.setHeader("Etag", getLatest_ETags());
}
}
//相同的服务地址,get请求获取自定义词库字符串
@RequestMapping(value="/es/getCustomDic",method=RequestMethod.GET,produces = {"text/html;charset=utf-8"})
public String getCustomDic(HttpServletRequest request,HttpServletResponse response) throws Exception{
String old_ETags=request.getHeader("If-None-Match");
logger.info("get请求,old_ETags="+old_ETags);
StringBuilder hotwordStr=new StringBuilder();
//先让热词状态改为生效状态
HWIceServiceClient.getServicePrx(HotWordIPrx.class).updateHotWordIsEffect("family");
//说明第一次请求或者最新标示已经更新
List<String> hotWord=HWIceServiceClient.getServicePrx(HotWordIPrx.class).getAllHotWords("family");
logger.info("新的热词加入,个数为: "+hotWord.size());
hotWord.forEach(str->{
hotwordStr.append(str+"\r\n");
});
refreshETags();
return hotwordStr.toString();
}
五、同义词
维护静态同义词词库
- 创建词库文件
>cd /opt/elasticsearch/elasticsearch-5.5.3/config
>mkdir analysis
>cd analysis
>vim synonyms.txt
西红柿,番茄,土豆,马铃薯
社保,公积金
- 创建索引,添加自定义分词器,指定同义词过滤器、同义词库文件地址
PUT /synonymtest
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"jt_cn": {
"type": "custom",
"use_smart": "true",
"tokenizer": "ik_smart",
"filter": ["jt_tfr","jt_sfr"],
"char_filter": ["jt_cfr"]
},
"ik_smart": {
"type": "ik_smart",
"use_smart": "true"
},
"ik_max_word": {
"type": "ik_max_word",
"use_smart": "false"
}
},
"filter": {
"jt_tfr": {
"type": "stop",
"stopwords": [" "]
},
"jt_sfr": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt" //这个是相对于${es_home}/config目录而言的地址
}
},
"char_filter": {
"jt_cfr": {
"type": "mapping",
"mappings": [
"| => \\|"
]
}
}
}
}
}
}
- 给文档字段创建映射,指定自定义分词器
PUT /synonymtest/mytype/_mapping
{
"mytype":{
"properties":{
"title":{
"analyzer":"jt_cn",
"term_vector":"with_positions_offsets",
"boost":8,
"store":true,
"type":"text"
}
}
}
}
- 添加数据
PUT /synonymtest/mytype/1
{
"title": "番茄"
}
PUT /synonymtest/mytype/2
{
"title": "西红柿"
}
PUT /synonymtest/mytype/3
{
"title": "我是西红柿"
}
PUT /synonymtest/mytype/4
{
"title": "我是番茄"
}
PUT /synonymtest/mytype/5
{
"title": "土豆"
}
PUT /synonymtest/mytype/6
{
"title": "aa"
}
- 搜索同义词
POST /synonymtest/mytype/_search?pretty
{
"query": {
"match_phrase": {
"title": {
"query": "西红柿",
"analyzer": "jt_cn"
}
}
},
"highlight": {
"pre_tags": [
"<tag1>",
"<tag2>"
],
"post_tags": [
"</tag1>",
"</tag2>"
],
"fields": {
"title": {}
}
}
}
维护动态同义词词库
- mysql创建同义词维护表
DROP TABLE IF EXISTS `synonym_config`;
CREATE TABLE `synonym_config` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`synonyms` varchar(128) DEFAULT NULL,
`last_update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
INSERT INTO `synonym_config` VALUES ('1', '西红柿,番茄,圣女果', '2019-04-01 16:10:16');
INSERT INTO `synonym_config` VALUES ('2', '馄饨,抄手', '2019-04-02 16:10:40');
INSERT INTO `synonym_config` VALUES ('5', '小说,笑说,晓说', '2019-03-31 17:23:36');
INSERT INTO `synonym_config` VALUES ('6', '你好,利好', '2019-04-02 17:27:06');
- 创建一个SpringBoot应用,用来提供同义词数据接口供ElasticSearch定期检查导入
- 编译打包动态同义词ES插件
elasticsearch-analysis-dynamic-synonym
mvn clean package
在target>release目录下找到xxx.zip,放到${es_home}/plugins/dynamic-synonym/下解压,重启ES
DELETE synonymtest
PUT synonymtest
{
"settings":{
"index":{
"analysis":{
"filter":{
"local_synonym":{
"type":"synonym",
"synonyms_path":"synonym.txt",
"interval":60
},
"http_synonym":{
"type":"dynamic_synonym",
"synonyms_path":"http://192.168.237.129:8080/synonym",
"interval":60
}
},
"analyzer":{
"ik_max_word_syno":{
"type":"custom",
"tokenizer":"ik_max_word",
"filter":[
"http_synonym"
]
},
"ik_smart_syno":{
"type":"custom",
"tokenizer":"ik_smart",
"filter":[
"http_synonym"
]
}
}
}
}
}
}
POST synonymtest/product/_mapping
{
"product":{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"text",
"analyzer":"ik_max_word_syno",
"search_analyzer":"ik_max_word_syno"
}
}
}
}
GET synonymtest/product/_mapping
PUT /synonymtest/product/1
{
"id":111,
"name":"番茄炒蛋"
}
PUT /synonymtest/product/2
{
"id":222,
"name":"西红柿炒蛋"
}
GET /synonymtest/product/_search
GET synonymtest/product/_search
{
"query": {
"match_phrase": {
"name": {
"query": "西红柿",
"analyzer": "ik_max_word_syno"
}
}
}
}
POST synonymtest/_analyze
{
"analyzer": "ik_max_word_syno",
"text": "西红柿"
}
六、扩容
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_scale_horizontally.html
七、原理
写数据原理,查询原理
refresh、flush
倒排索引
Elasticsearch 如何做到快速检索 - 倒排索引的秘密
八、Java SDK
问题
- translog是什么?
- match、match_phrase、term、bool区别
Elasticsearch查询match、term和bool区别
- keyword、text区别
- segment是什么?
- 创建doc的过程
协调节点hash取模shard = hash(document_id) % (num_of_primary_shards),确定在哪个分片,分片所在节点写入Memory Buffer,默认1秒refresh一次到Filesystem Cache,写入translog,flush到磁盘(30分钟一次,或translog大于512M)。flush之后新的translog被创建老的删除,MemoryBuffer写入新segment然后清空,写入新的提交点。
- 删除/更新doc的过程
ES中的doc是不可变的,删除是在磁盘上segment对应的.del文件中做标记,更新一样,只是把老的version的doc标记删除,查询的时候标记删除的记录依然可以匹配查询,但是会被过滤掉。在
- 搜索的过程
- ES是如何做master选举的?集群脑裂怎么解决?
ZenDiscovery模块,nodeId排序,达到n/2+1
通过最少master候选节点配置来解决脑裂问题,集群最少3个节点
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}
- 如何保证并发读写一致?
乐观锁版本号
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
参考
Java代理
2019-03-18 网络 java-basics java-basics- content
前言
总结Java代理相关基础知识
课程目录
- 静态代理
- 动态代理(JDK动态代理、cglib动态代理)
静态代理
优点:
- 代理对象可以在不修改目标对象的情况下扩展和拦截目标对象行为
缺点:
- 代理对象和目标对象要实现共同接口,被代理对象改变,代理对象也要跟着变
//共同接口
public interface MyInterface {
void doSomething();
}
//被代理对象
public class MyClass implements MyInterface {
@Override
public void doSomething() {
System.out.println("something...");
}
}
//代理对象
public class MyProxy implements MyInterface {
private MyInterface target;
public MyProxy(MyInterface target){
this.target = target;
}
@Override
public void doSomething() {
System.out.println("before doSomething...");
target.doSomething();
System.out.println("after doSomething...");
}
}
//测试静态代理
public class StaticProxyTest {
public static void main(String[] args) {
MyClass target=new MyClass();
MyProxy proxy=new MyProxy(target);
proxy.doSomething();
}
}
动态代理
JDK动态代理
java.lang.reflect 包提供了一个Proxy类和一个InvocationHandler接口,用来生成JDK动态代理类和动态代理对象。
//省略相同的接口及目标实现对象...
//创建一个调用处理器来通过反射的方式处理目标对象行为
public class MyInvocationHandler implements InvocationHandler {
private Object target;
public MyInvocationHandler(Object target){
this.target=target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("before...");
Object result = method.invoke(target,args);
System.out.println("after...");
return result;
}
}
//测试类
public class DynamicProxyTest {
public static void main(String[] args) {
//目标对象
MyInterface target=new MyClass();
//代理
MyInvocationHandler myInvocationHandler=new MyInvocationHandler(target);
MyInterface proxy=(MyInterface)Proxy.newProxyInstance(target.getClass().getClassLoader(),target.getClass().getInterfaces(),myInvocationHandler);
proxy.doSomething();
}
}
当然每次需要代理一个对象都创建这么一个InvocationHandler很不方便,可以封装出来一个代理工厂,生产通用的代理对象
//代理工厂类
public class ProxyFactory {
//给目标对象生成代理对象
public static Object getProxyInstance(Object target){
return Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
(proxy, method, args) -> {
System.out.println("before...");
//执行目标对象方法
Object returnValue = method.invoke(target, args);
System.out.println("after...");
return returnValue;
}
);
}
}
//测试类
public class DynamicProxyTest {
public static void main(String[] args) {
MyInterface target=new MyClass();
MyInterface proxy = (MyInterface)ProxyFactory.getProxyInstance(target);
proxy.doSomething();
}
}
生成代理类的过程如下:
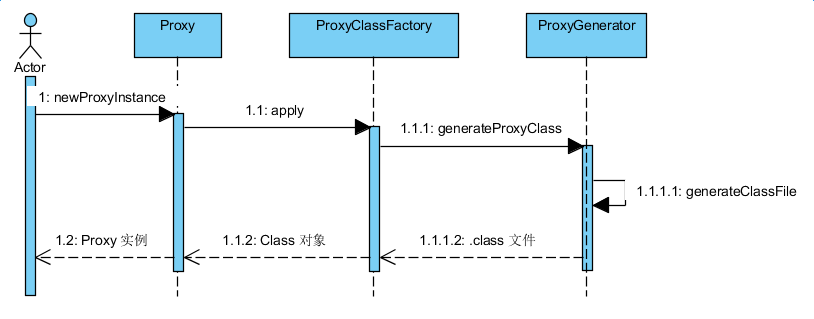
缺点:
- JDK动态代理也是需要目标对象实现一个接口的
- 使用反射机制来创建代理对象,性能据说较差
cglib动态代理(子类代理)
<!-- 引入cglib包 -->
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.2.7</version>
</dependency>
//目标对象
public class MyClassWithoutInterface {
public void doSomething() {
System.out.println("something...");
}
}
//代理类
public class MyCglibProxy implements MethodInterceptor {
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
System.out.println("before...");
Object o1 = methodProxy.invokeSuper(o, args);
System.out.println("after...");
return o1;
}
}
//测试类
public class CglibTest {
public static void main(String[] args) {
Enhancer enhancer=new Enhancer();
enhancer.setSuperclass(MyClassWithoutInterface.class);
enhancer.setCallback(new MyCglibProxy());
MyClassWithoutInterface myClass = (MyClassWithoutInterface)enhancer.create();
myClass.doSomething();
}
}
同样的,也可以创建一个通用的代理工厂
/**
* Cglib子类代理工厂
*/
public class ProxyFactory implements MethodInterceptor {
private Object target;
public ProxyFactory(Object target) {
this.target = target;
}
//给目标对象创建一个代理对象
public Object getProxyInstance(){
//1.工具类
Enhancer en = new Enhancer();
//2.设置父类
en.setSuperclass(target.getClass());
//3.设置回调函数
en.setCallback(this);
//4.创建子类(代理对象)
return en.create();
}
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("before...");
Object returnValue = method.invoke(target, args);
System.out.println("after...");
return returnValue;
}
}
//测试类
public class CglibTest {
public static void main(String[] args) {
MyClassWithoutInterface target = new MyClassWithoutInterface();
MyClassWithoutInterface proxy = (MyClassWithoutInterface)new ProxyFactory(target).getProxyInstance();
proxy.doSomething();
}
}
优点:
- 不需要目标对象实现接口,内存中动态创建子类的方式来创建代理类,所以被代理目标对象不能是final类
- 使用ASM字节码技术,性能据说好一些
在Spring的AOP编程中:
- 如果加入容器的目标对象有实现接口,用JDK代理
- 如果目标对象没有实现接口,用Cglib代理
参考
ClassLoader
2019-03-12 转载 JVM JVM- content
前言
深入理解Java类加载器(ClassLoader)
课程目录
本篇博文主要是探讨类加载器,同时在本篇中列举的源码都基于Java8版本,不同的版本可能有些许差异。主要内容如下:
- 类加载的机制的层次结构
- 启动Bootstrap类加载器
- 扩展Extension类加载器
- 系统System类加载器
- 理解双亲委派模式
- 双亲委派模式工作原理
- 双亲委派模式优势
- 类加载器间的关系
- 类与类加载器
- 类与类加载器
- 了解class文件的显示加载与隐式加载的概念
- 编写自己的类加载器
- 自定义File类加载器
- 自定义网络类加载器
- 热部署类加载器
- 双亲委派模型的破坏者-线程上下文类加载器
类加载的机制的层次结构
每个编写的”.java”拓展名类文件都存储着需要执行的程序逻辑,这些”.java”文件经过Java编译器编译成拓展名为”.class”的文件,”.class”文件中保存着Java代码经转换后的虚拟机指令,当需要使用某个类时,虚拟机将会加载它的”.class”文件,并创建对应的class对象,将class文件加载到虚拟机的内存,这个过程称为类加载,这里我们需要了解一下类加载的过程,如下:
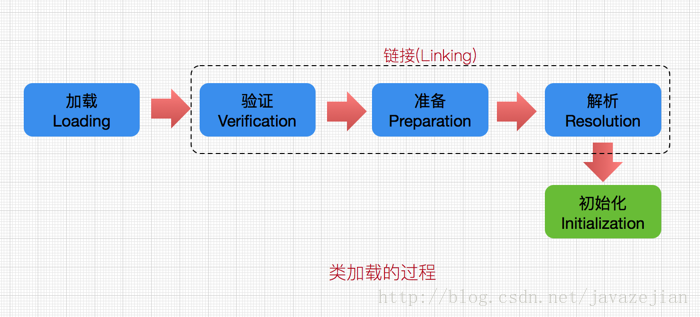
- 加载:类加载过程的一个阶段:通过一个类的完全限定查找此类字节码文件,并利用字节码文件创建一个Class对象
- 验证:目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身安全。主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
- 准备:为类变量(也叫静态变量,即static修饰的字段变量)分配内存并且设置该类变量的初始值即0(如static int i=5;这里只将i初始化为0,至于5的值将在初始化时赋值),这里不包含用final修饰的static,因为final在编译的时候就会分配了,注意这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量是会随着对象一起分配到Java堆中。
- 解析:主要将常量池中的符号引用替换为直接引用的过程。符号引用就是一组符号来描述目标,可以是任何字面量,而直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。有类或接口的解析,字段解析,类方法解析,接口方法解析(这里涉及到字节码变量的引用,如需更详细了解,可参考《深入Java虚拟机》)。
- 初始化:类加载最后阶段,若该类具有超类,则对其进行初始化,执行静态初始化器和静态初始化成员变量(如前面只初始化了默认值的static变量将会在这个阶段赋值,成员变量也将被初始化)。 前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
这便是类加载的5个过程,而类加载器的任务是根据一个类的全限定名来读取此类的二进制字节流到JVM中,然后转换为一个与目标类对应的java.lang.Class对象实例,在虚拟机提供了3种类加载器,引导(Bootstrap)类加载器、扩展(Extension)类加载器、系统(System)类加载器(也称应用类加载器),下面分别介绍。
启动(Bootstrap)类加载器
启动类加载器主要加载的是JVM自身需要的类,这个类加载使用C++语言实现的,是虚拟机自身的一部分,它负责将 <JAVA_HOME>/lib路径下的核心类库或-Xbootclasspath参数指定的路径下的jar包加载到内存中,注意由于虚拟机是按照文件名识别加载jar包的,如rt.jar,如果文件名不被虚拟机识别,即使把jar包丢到lib目录下也是没有作用的(出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类)。
扩展(Extension)类加载器
扩展类加载器是指Sun公司(已被Oracle收购)实现的sun.misc.Launcher$ExtClassLoader类,由Java语言实现的,是Launcher的静态内部类,它负责加载<JAVA_HOME>/lib/ext目录下或者由系统变量-Djava.ext.dir指定位路径中的类库,开发者可以直接使用标准扩展类加载器。
//ExtClassLoader类中获取路径的代码
private static File[] getExtDirs() {
//加载<JAVA_HOME>/lib/ext目录中的类库
String s = System.getProperty("java.ext.dirs");
File[] dirs;
if (s != null) {
StringTokenizer st =
new StringTokenizer(s, File.pathSeparator);
int count = st.countTokens();
dirs = new File[count];
for (int i = 0; i < count; i++) {
dirs[i] = new File(st.nextToken());
}
} else {
dirs = new File[0];
}
return dirs;
}
系统(System)类加载器
也称应用程序加载器是指 Sun公司实现的sun.misc.Launcher$AppClassLoader。它负责加载系统类路径java -classpath或-D java.class.path 指定路径下的类库,也就是我们经常用到的classpath路径,开发者可以直接使用系统类加载器,一般情况下该类加载是程序中默认的类加载器,通过ClassLoader#getSystemClassLoader()方法可以获取到该类加载器。
在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,需要注意的是,Java虚拟机对class文件采用的是按需加载的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成class对象,而且加载某个类的class文件时,Java虚拟机采用的是双亲委派模式即把请求交由父类处理,它一种任务委派模式,下面我们进一步了解它。
理解双亲委派模式
双亲委派模式工作原理
双亲委派模式要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器,请注意双亲委派模式中的父子关系并非通常所说的类继承关系,而是采用组合关系来复用父类加载器的相关代码,类加载器间的关系如下:
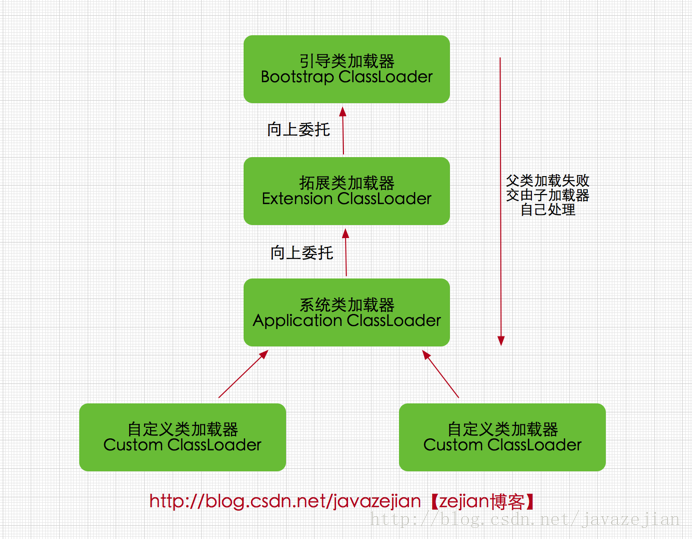
双亲委派模式是在Java 1.2后引入的,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己想办法去完成,这不就是传说中的实力坑爹啊?那么采用这种模式有啥用呢?
双亲委派模式优势
采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。可能你会想,如果我们在classpath路径下自定义一个名为java.lang.SingleInterge类(该类是胡编的)呢?该类并不存在java.lang中,经过双亲委托模式,传递到启动类加载器中,由于父类加载器路径下并没有该类,所以不会加载,将反向委托给子类加载器加载,最终会通过系统类加载器加载该类。但是这样做是不允许,因为java.lang是核心API包,需要访问权限,强制加载将会报出如下异常:
java.lang.SecurityException: Prohibited package name: java.lang
所以无论如何都无法加载成功的。下面我们从代码层面了解几个Java中定义的类加载器及其双亲委派模式的实现,它们类图关系如下:
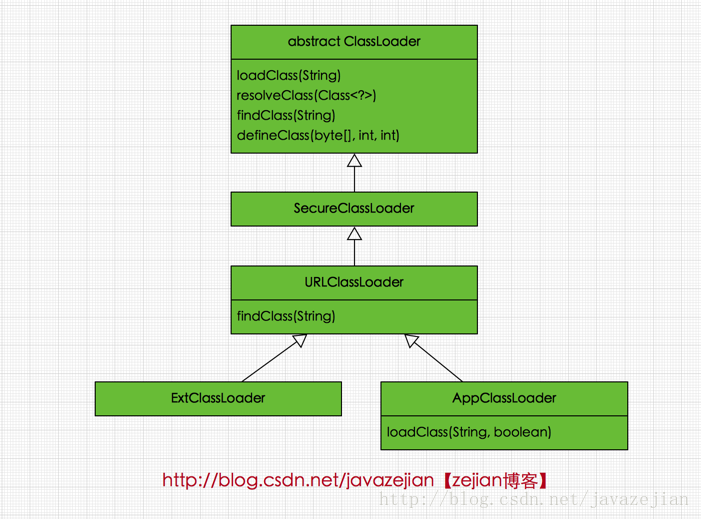
图可以看出顶层的类加载器是ClassLoader类,它是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器),这里我们主要介绍ClassLoader中几个比较重要的方法。
- loadClass(String)
该方法加载指定名称(包括包名)的二进制类型,该方法在JDK1.2之后不再建议用户重写但用户可以直接调用该方法,loadClass()方法是ClassLoader类自己实现的,该方法中的逻辑就是双亲委派模式的实现,其源码如下,loadClass(String name, boolean resolve)是一个重载方法,resolve参数代表是否生成class对象的同时进行解析相关操作。
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 先从缓存查找该class对象,找到就不用重新加载
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//如果找不到,则委托给父类加载器去加载
c = parent.loadClass(name, false);
} else {
//如果没有父类,则委托给启动加载器去加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// 如果都没有找到,则通过自定义实现的findClass去查找并加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {//是否需要在加载时进行解析
resolveClass(c);
}
return c;
}
}
正如loadClass方法所展示的,当类加载请求到来时,先从缓存中查找该类对象,如果存在直接返回,如果不存在则交给该类加载去的父加载器去加载,倘若没有父加载则交给顶级启动类加载器去加载,最后倘若仍没有找到,则使用findClass()方法去加载(关于findClass()稍后会进一步介绍)。从loadClass实现也可以知道如果不想重新定义加载类的规则,也没有复杂的逻辑,只想在运行时加载自己指定的类,那么我们可以直接使用this.getClass().getClassLoder.loadClass("className"),这样就可以直接调用ClassLoader的loadClass方法获取到class对象。
- findClass(String)
在JDK1.2之前,在自定义类加载时,总会去继承ClassLoader类并重写loadClass方法,从而实现自定义的类加载类,但是在JDK1.2之后已不再建议用户去覆盖loadClass()方法,而是建议把自定义的类加载逻辑写在findClass()方法中,从前面的分析可知,findClass()方法是在loadClass()方法中被调用的,当loadClass()方法中父加载器加载失败后,则会调用自己的findClass()方法来完成类加载,这样就可以保证自定义的类加载器也符合双亲委托模式。需要注意的是ClassLoader类中并没有实现findClass()方法的具体代码逻辑,取而代之的是抛出ClassNotFoundException异常,同时应该知道的是findClass方法通常是和defineClass方法一起使用的(稍后会分析),ClassLoader类中findClass()方法源码如下:
//直接抛出异常
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
- defineClass(byte[] b, int off, int len)
defineClass()方法是用来将byte字节流解析成JVM能够识别的Class对象(ClassLoader中已实现该方法逻辑),通过这个方法不仅能够通过class文件实例化class对象,也可以通过其他方式实例化class对象,如通过网络接收一个类的字节码,然后转换为byte字节流创建对应的Class对象,defineClass()方法通常与findClass()方法一起使用,一般情况下,在自定义类加载器时,会直接覆盖ClassLoader的findClass()方法并编写加载规则,取得要加载类的字节码后转换成流,然后调用defineClass()方法生成类的Class对象,简单例子如下:
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 获取类的字节数组
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
//使用defineClass生成class对象
return defineClass(name, classData, 0, classData.length);
}
}
需要注意的是,如果直接调用defineClass()方法生成类的Class对象,这个类的Class对象并没有解析(也可以理解为链接阶段,毕竟解析是链接的最后一步),其解析操作需要等待初始化阶段进行。
- resolveClass(Class≺?≻ c)
使用该方法可以使用类的Class对象创建完成也同时被解析。前面我们说链接阶段主要是对字节码进行验证,为类变量分配内存并设置初始值同时将字节码文件中的符号引用转换为直接引用。
上述4个方法是ClassLoader类中的比较重要的方法,也是我们可能会经常用到的方法。接看SercureClassLoader扩展了 ClassLoader,新增了几个与使用相关的代码源(对代码源的位置及其证书的验证)和权限定义类验证(主要指对class源码的访问权限)的方法,一般我们不会直接跟这个类打交道,更多是与它的子类URLClassLoader有所关联,前面说过,ClassLoader是一个抽象类,很多方法是空的没有实现,比如 findClass()、findResource()等。而URLClassLoader这个实现类为这些方法提供了具体的实现,并新增了URLClassPath类协助取得Class字节码流等功能,在编写自定义类加载器时,如果没有太过于复杂的需求,可以直接继承URLClassLoader类,这样就可以避免自己去编写findClass()方法及其获取字节码流的方式,使自定义类加载器编写更加简洁,下面是URLClassLoader的类图(利用IDEA生成的类图)
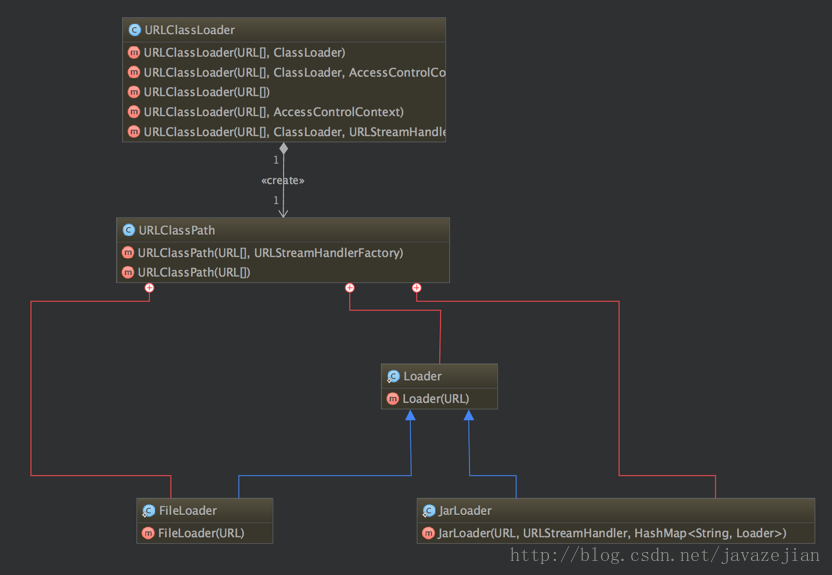
类图结构看出URLClassLoader中存在一个URLClassPath类,通过这个类就可以找到要加载的字节码流,也就是说URLClassPath类负责找到要加载的字节码,再读取成字节流,最后通过defineClass()方法创建类的Class对象。从URLClassLoader类的结构图可以看出其构造方法都有一个必须传递的参数URL[],该参数的元素是代表字节码文件的路径,换句话说在创建URLClassLoader对象时必须要指定这个类加载器的到那个目录下找class文件。同时也应该注意URL[]也是URLClassPath类的必传参数,在创建URLClassPath对象时,会根据传递过来的URL数组中的路径判断是文件还是jar包,然后根据不同的路径创建FileLoader或者JarLoader或默认Loader类去加载相应路径下的class文件,而当JVM调用findClass()方法时,就由这3个加载器中的一个将class文件的字节码流加载到内存中,最后利用字节码流创建类的class对象。请记住,如果我们在定义类加载器时选择继承ClassLoader类而非URLClassLoader,必须手动编写findclass()方法的加载逻辑以及获取字节码流的逻辑。了解完URLClassLoader后接着看看剩余的两个类加载器,即拓展类加载器ExtClassLoader和系统类加载器AppClassLoader,这两个类都继承自URLClassLoader,是sun.misc.Launcher的静态内部类。sun.misc.Launcher主要被系统用于启动主应用程序,ExtClassLoader和AppClassLoader都是由sun.misc.Launcher创建的,其类主要类结构如下:
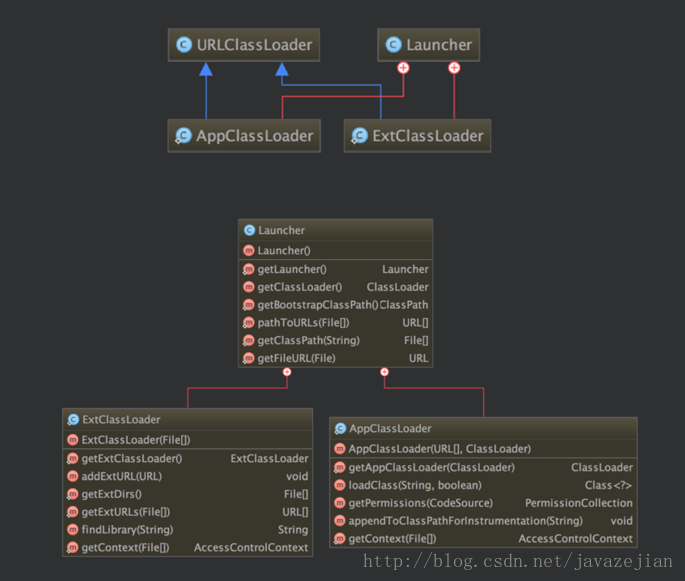
他们间的关系正如前面所阐述的那样,同时我们发现ExtClassLoader并没有重写loadClass()方法,这足矣说明其遵循双亲委派模式,而AppClassLoader重载了loadCass()方法,但最终调用的还是父类loadClass()方法,因此依然遵守双亲委派模式,重载方法源码如下:
/**
* Override loadClass 方法,新增包权限检测功能
*/
public Class loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
int i = name.lastIndexOf('.');
if (i != -1) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPackageAccess(name.substring(0, i));
}
}
//依然调用父类的方法
return (super.loadClass(name, resolve));
}
其实无论是ExtClassLoader还是AppClassLoader都继承URLClassLoader类,因此它们都遵守双亲委托模型,这点是毋庸置疑的。ok~,到此我们对ClassLoader、URLClassLoader、ExtClassLoader、AppClassLoader以及Launcher类间的关系有了比较清晰的了解,同时对一些主要的方法也有一定的认识,这里并没有对这些类的源码进行详细的分析,毕竟没有那个必要,因为我们主要弄得类与类间的关系和常用的方法同时搞清楚双亲委托模式的实现过程,为编写自定义类加载器做铺垫就足够了。ok~,前面出现了很多父类加载器的说法,但每个类加载器的父类到底是谁,一直没有阐明,下面我们就通过代码验证的方式来阐明这答案。
类加载器间的关系
我们进一步了解类加载器间的关系(并非指继承关系),主要可以分为以下4点
- 启动类加载器,由C++实现,没有父类。
- 拓展类加载器(ExtClassLoader),由Java语言实现,父类加载器为null
- 系统类加载器(AppClassLoader),由Java语言实现,父类加载器为ExtClassLoader
- 自定义类加载器,父类加载器肯定为AppClassLoader。
下面我们通过程序来验证上述阐述的观点
/**
* Created by zejian on 2017/6/18.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
//自定义ClassLoader,完整代码稍后分析
class FileClassLoader extends ClassLoader{
private String rootDir;
public FileClassLoader(String rootDir) {
this.rootDir = rootDir;
}
// 编写获取类的字节码并创建class对象的逻辑
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
//...省略逻辑代码
}
//编写读取字节流的方法
private byte[] getClassData(String className) {
// 读取类文件的字节
//省略代码....
}
}
public class ClassLoaderTest {
public static void main(String[] args) throws ClassNotFoundException {
FileClassLoader loader1 = new FileClassLoader(rootDir);
System.out.println("自定义类加载器的父加载器: "+loader1.getParent());
System.out.println("系统默认的AppClassLoader: "+ClassLoader.getSystemClassLoader());
System.out.println("AppClassLoader的父类加载器: "+ClassLoader.getSystemClassLoader().getParent());
System.out.println("ExtClassLoader的父类加载器: "+ClassLoader.getSystemClassLoader().getParent().getParent());
/**
输出结果:
自定义类加载器的父加载器: sun.misc.Launcher$AppClassLoader@29453f44
系统默认的AppClassLoader: sun.misc.Launcher$AppClassLoader@29453f44
AppClassLoader的父类加载器: sun.misc.Launcher$ExtClassLoader@6f94fa3e
ExtClassLoader的父类加载器: null
*/
}
}
代码中,我们自定义了一个FileClassLoader,这里我们继承了ClassLoader而非URLClassLoader,因此需要自己编写findClass()方法逻辑以及加载字节码的逻辑,关于自定义类加载器我们稍后会分析,这里仅需要知道FileClassLoader是自定义加载器即可,接着在main方法中,通过ClassLoader.getSystemClassLoader()获取到系统默认类加载器,通过获取其父类加载器及其父父类加载器,同时还获取了自定义类加载器的父类加载器,最终输出结果正如我们所预料的,AppClassLoader的父类加载器为ExtClassLoader,而ExtClassLoader没有父类加载器。如果我们实现自己的类加载器,它的父加载器都只会是AppClassLoader。这里我们不妨看看Lancher的构造器源码
public Launcher() {
// 首先创建拓展类加载器
ClassLoader extcl;
try {
extcl = ExtClassLoader.getExtClassLoader();
} catch (IOException e) {
throw new InternalError(
"Could not create extension class loader");
}
// Now create the class loader to use to launch the application
try {
//再创建AppClassLoader并把extcl作为父加载器传递给AppClassLoader
loader = AppClassLoader.getAppClassLoader(extcl);
} catch (IOException e) {
throw new InternalError(
"Could not create application class loader");
}
//设置线程上下文类加载器,稍后分析
Thread.currentThread().setContextClassLoader(loader);
//省略其他没必要的代码......
}
显然Lancher初始化时首先会创建ExtClassLoader类加载器,然后再创建AppClassLoader并把ExtClassLoader传递给它作为父类加载器,这里还把AppClassLoader默认设置为线程上下文类加载器,关于线程上下文类加载器稍后会分析。那ExtClassLoader类加载器为什么是null呢?看下面的源码创建过程就明白,在创建ExtClassLoader强制设置了其父加载器为null。
//Lancher中创建ExtClassLoader
extcl = ExtClassLoader.getExtClassLoader();
//getExtClassLoader()方法
public static ExtClassLoader getExtClassLoader() throws IOException{
//........省略其他代码
return new ExtClassLoader(dirs);
// .........
}
//构造方法
public ExtClassLoader(File[] dirs) throws IOException {
//调用父类构造URLClassLoader传递null作为parent
super(getExtURLs(dirs), null, factory);
}
//URLClassLoader构造
public URLClassLoader(URL[] urls, ClassLoader parent, URLStreamHandlerFactory factory) {
//...
}
显然ExtClassLoader的父类为null,而AppClassLoader的父加载器为ExtClassLoader,所有自定义的类加载器其父加载器只会是AppClassLoader,注意这里所指的父类并不是Java继承关系中的那种父子关系。
类与类加载器
类与类加载器
在JVM中表示两个class对象是否为同一个类对象存在两个必要条件:
- 类的完整类名必须一致,包括包名。
- 加载这个类的ClassLoader(指ClassLoader实例对象)必须相同。
也就是说,在JVM中,即使这个两个类对象(class对象)来源同一个Class文件,被同一个虚拟机所加载,但只要加载它们的ClassLoader实例对象不同,那么这两个类对象也是不相等的,这是因为不同的ClassLoader实例对象都拥有不同的独立的类名称空间,所以加载的class对象也会存在不同的类名空间中,但前提是覆写loadclass方法,从前面双亲委派模式对loadClass()方法的源码分析中可以知,在方法第一步会通过Class<?> c = findLoadedClass(name);从缓存查找,类名完整名称相同则不会再次被加载,因此我们必须绕过缓存查询才能重新加载class对象。当然也可直接调用findClass()方法,这样也避免从缓存查找,如下:
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建两个不同的自定义类加载器实例
FileClassLoader loader1 = new FileClassLoader(rootDir);
FileClassLoader loader2 = new FileClassLoader(rootDir);
//通过findClass创建类的Class对象
Class<?> object1=loader1.findClass("com.zejian.classloader.DemoObj");
Class<?> object2=loader2.findClass("com.zejian.classloader.DemoObj");
System.out.println("findClass->obj1:"+object1.hashCode());
System.out.println("findClass->obj2:"+object2.hashCode());
/**
* 直接调用findClass方法输出结果:
* findClass->obj1:723074861
findClass->obj2:895328852
生成不同的实例
*/
如果调用父类的loadClass方法,结果如下,除非重写loadClass()方法去掉缓存查找步骤,不过现在一般都不建议重写loadClass()方法。
//直接调用父类的loadClass()方法
Class<?> obj1 =loader1.loadClass("com.zejian.classloader.DemoObj");
Class<?> obj2 =loader2.loadClass("com.zejian.classloader.DemoObj");
//不同实例对象的自定义类加载器
System.out.println("loadClass->obj1:"+obj1.hashCode());
System.out.println("loadClass->obj2:"+obj2.hashCode());
//系统类加载器
System.out.println("Class->obj3:"+DemoObj.class.hashCode());
/**
* 直接调用loadClass方法的输出结果,注意并没有重写loadClass方法
* loadClass->obj1:1872034366
loadClass->obj2:1872034366
Class-> obj3:1872034366
都是同一个实例
*/
所以如果不从缓存查询相同完全类名的class对象,那么只有ClassLoader的实例对象不同,同一字节码文件创建的class对象自然也不会相同。
了解class文件的显式加载与隐式加载的概念
所谓class文件的显式加载与隐式加载的方式是指JVM加载class文件到内存的方式,显式加载指的是在代码中通过调用ClassLoader加载class对象,如直接使用Class.forName(name)或this.getClass().getClassLoader().loadClass()加载class对象。而隐式加载则是不直接在代码中调用ClassLoader的方法加载class对象,而是通过虚拟机自动加载到内存中,如在加载某个类的class文件时,该类的class文件中引用了另外一个类的对象,此时额外引用的类将通过JVM自动加载到内存中。在日常开发以上两种方式一般会混合使用,这里我们知道有这么回事即可。
编写自己的类加载器
通过前面的分析可知,实现自定义类加载器需要继承ClassLoader或者URLClassLoader,继承ClassLoader则需要自己重写findClass()方法并编写加载逻辑,继承URLClassLoader则可以省去编写findClass()方法以及class文件加载转换成字节码流的代码。那么编写自定义类加载器的意义何在呢?
- 当class文件不在ClassPath路径下,默认系统类加载器无法找到该class文件,在这种情况下我们需要实现一个自定义的ClassLoader来加载特定路径下的class文件生成class对象。
- 当一个class文件是通过网络传输并且可能会进行相应的加密操作时,需要先对class文件进行相应的解密后再加载到JVM内存中,这种情况下也需要编写自定义的ClassLoader并实现相应的逻辑。
- 当需要实现热部署功能时(一个class文件通过不同的类加载器产生不同class对象从而实现热部署功能),需要实现自定义ClassLoader的逻辑。
自定义File类加载器
这里我们继承ClassLoader实现自定义的特定路径下的文件类加载器并加载编译后DemoObj.class,源码代码如下:
public class DemoObj {
@Override
public String toString() {
return "I am DemoObj";
}
}
import java.io.*;
/**
* Created by zejian on 2017/6/21.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class FileClassLoader extends ClassLoader {
private String rootDir;
public FileClassLoader(String rootDir) {
this.rootDir = rootDir;
}
/**
* 编写findClass方法的逻辑
* @param name
* @return
* @throws ClassNotFoundException
*/
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 获取类的class文件字节数组
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
//直接生成class对象
return defineClass(name, classData, 0, classData.length);
}
}
/**
* 编写获取class文件并转换为字节码流的逻辑
* @param className
* @return
*/
private byte[] getClassData(String className) {
// 读取类文件的字节
String path = classNameToPath(className);
try {
InputStream ins = new FileInputStream(path);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead = 0;
// 读取类文件的字节码
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 类文件的完全路径
* @param className
* @return
*/
private String classNameToPath(String className) {
return rootDir + File.separatorChar
+ className.replace('.', File.separatorChar) + ".class";
}
public static void main(String[] args) throws ClassNotFoundException {
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建自定义文件类加载器
FileClassLoader loader = new FileClassLoader(rootDir);
try {
//加载指定的class文件
Class<?> object1=loader.loadClass("com.zejian.classloader.DemoObj");
System.out.println(object1.newInstance().toString());
//输出结果:I am DemoObj
} catch (Exception e) {
e.printStackTrace();
}
}
}
显然我们通过getClassData()方法找到class文件并转换为字节流,并重写findClass()方法,利用defineClass()方法创建了类的class对象。在main方法中调用了loadClass()方法加载指定路径下的class文件,由于启动类加载器、拓展类加载器以及系统类加载器都无法在其路径下找到该类,因此最终将有自定义类加载器加载,即调用findClass()方法进行加载。如果继承URLClassLoader实现,那代码就更简洁了,如下:
/**
* Created by zejian on 2017/6/21.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class FileUrlClassLoader extends URLClassLoader {
public FileUrlClassLoader(URL[] urls, ClassLoader parent) {
super(urls, parent);
}
public FileUrlClassLoader(URL[] urls) {
super(urls);
}
public FileUrlClassLoader(URL[] urls, ClassLoader parent, URLStreamHandlerFactory factory) {
super(urls, parent, factory);
}
public static void main(String[] args) throws ClassNotFoundException, MalformedURLException {
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建自定义文件类加载器
File file = new File(rootDir);
//File to URI
URI uri=file.toURI();
URL[] urls={uri.toURL()};
FileUrlClassLoader loader = new FileUrlClassLoader(urls);
try {
//加载指定的class文件
Class<?> object1=loader.loadClass("com.zejian.classloader.DemoObj");
System.out.println(object1.newInstance().toString());
//输出结果:I am DemoObj
} catch (Exception e) {
e.printStackTrace();
}
}
}
非常简洁除了需要重写构造器外无需编写findClass()方法及其class文件的字节流转换逻辑。
自定义网络类加载器
自定义网络类加载器,主要用于读取通过网络传递的class文件(在这里我们省略class文件的解密过程),并将其转换成字节流生成对应的class对象,如下:
/**
* Created by zejian on 2017/6/21.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class NetClassLoader extends ClassLoader {
private String url;//class文件的URL
public NetClassLoader(String url) {
this.url = url;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = getClassDataFromNet(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
return defineClass(name, classData, 0, classData.length);
}
}
/**
* 从网络获取class文件
* @param className
* @return
*/
private byte[] getClassDataFromNet(String className) {
String path = classNameToPath(className);
try {
URL url = new URL(path);
InputStream ins = url.openStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead = 0;
// 读取类文件的字节
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
//这里省略解密的过程.......
return baos.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
private String classNameToPath(String className) {
// 得到类文件的URL
return url + "/" + className.replace('.', '/') + ".class";
}
}
比较简单,主要是在获取字节码流时的区别,从网络直接获取到字节流再转车字节数组然后利用defineClass方法创建class对象,如果继承URLClassLoader类则和前面文件路径的实现是类似的,无需担心路径是filePath还是Url,因为URLClassLoader内的URLClassPath对象会根据传递过来的URL数组中的路径判断是文件还是jar包,然后根据不同的路径创建FileLoader或者JarLoader或默认类Loader去读取对于的路径或者url下的class文件。
热部署类加载器
所谓的热部署就是利用同一个class文件不同的类加载器在内存创建出两个不同的class对象(关于这点的原因前面已分析过,即利用不同的类加载实例),由于JVM在加载类之前会检测请求的类是否已加载过(即在loadClass()方法中调用findLoadedClass()方法),如果被加载过,则直接从缓存获取,不会重新加载。注意同一个类加载器的实例和同一个class文件只能被加载器一次,多次加载将报错,因此我们实现的热部署必须让同一个class文件可以根据不同的类加载器重复加载,以实现所谓的热部署。实际上前面的实现的FileClassLoader和FileUrlClassLoader已具备这个功能,但前提是直接调用findClass()方法,而不是调用loadClass()方法,因为ClassLoader中loadClass()方法体中调用findLoadedClass()方法进行了检测是否已被加载,因此我们直接调用findClass()方法就可以绕过这个问题,当然也可以重新loadClass方法,但强烈不建议这么干。利用FileClassLoader类测试代码如下:
public static void main(String[] args) throws ClassNotFoundException {
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建自定义文件类加载器
FileClassLoader loader = new FileClassLoader(rootDir);
FileClassLoader loader2 = new FileClassLoader(rootDir);
try {
//加载指定的class文件,调用loadClass()
Class<?> object1=loader.loadClass("com.zejian.classloader.DemoObj");
Class<?> object2=loader2.loadClass("com.zejian.classloader.DemoObj");
System.out.println("loadClass->obj1:"+object1.hashCode());
System.out.println("loadClass->obj2:"+object2.hashCode());
//加载指定的class文件,直接调用findClass(),绕过检测机制,创建不同class对象。
Class<?> object3=loader.findClass("com.zejian.classloader.DemoObj");
Class<?> object4=loader2.findClass("com.zejian.classloader.DemoObj");
System.out.println("loadClass->obj3:"+object3.hashCode());
System.out.println("loadClass->obj4:"+object4.hashCode());
/**
* 输出结果:
* loadClass->obj1:644117698
loadClass->obj2:644117698
findClass->obj3:723074861
findClass->obj4:895328852
*/
} catch (Exception e) {
e.printStackTrace();
}
}
双亲委派模型的破坏者-线程上下文类加载器
在Java应用中存在着很多服务提供者接口(Service Provider Interface,SPI),这些接口允许第三方为它们提供实现,如常见的 SPI 有 JDBC、JNDI等,这些 SPI 的接口属于 Java 核心库,一般存在rt.jar包中,由Bootstrap类加载器加载,而 SPI 的第三方实现代码则是作为Java应用所依赖的 jar 包被存放在classpath路径下,由于SPI接口中的代码经常需要加载具体的第三方实现类并调用其相关方法,但SPI的核心接口类是由引导类加载器来加载的,而Bootstrap类加载器无法直接加载SPI的实现类,同时由于双亲委派模式的存在,Bootstrap类加载器也无法反向委托AppClassLoader加载器SPI的实现类。在这种情况下,我们就需要一种特殊的类加载器来加载第三方的类库,而线程上下文类加载器就是很好的选择。
线程上下文类加载器(contextClassLoader)是从 JDK 1.2 开始引入的,我们可以通过java.lang.Thread类中的getContextClassLoader()和 setContextClassLoader(ClassLoader cl)方法来获取和设置线程的上下文类加载器。如果没有手动设置上下文类加载器,线程将继承其父线程的上下文类加载器,初始线程的上下文类加载器是系统类加载器(AppClassLoader),在线程中运行的代码可以通过此类加载器来加载类和资源,如下图所示,以jdbc.jar加载为例:
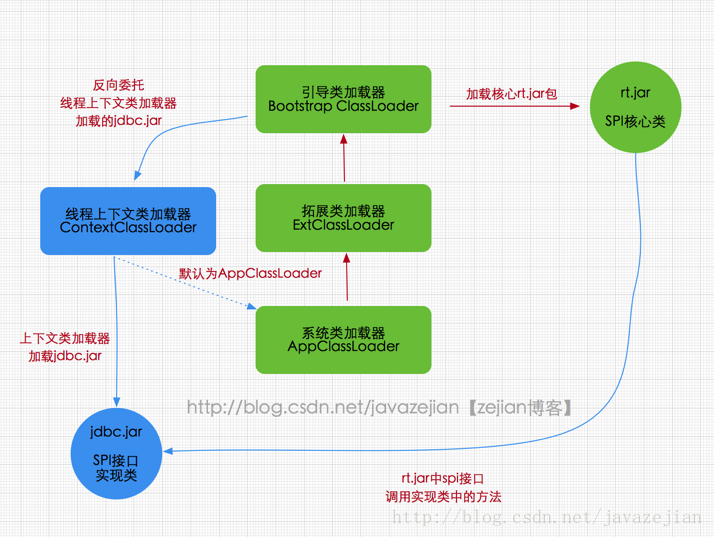
由图可知rt.jar核心包是由Bootstrap类加载器加载的,其内包含SPI核心接口类,由于SPI中的类经常需要调用外部实现类的方法,而jdbc.jar包含外部实现类(jdbc.jar存在于classpath路径)无法通过Bootstrap类加载器加载,因此只能委派线程上下文类加载器把jdbc.jar中的实现类加载到内存以便SPI相关类使用。显然这种线程上下文类加载器的加载方式破坏了“双亲委派模型”,它在执行过程中抛弃双亲委派加载链模式,使程序可以逆向使用类加载器,当然这也使得Java类加载器变得更加灵活。为了进一步证实这种场景,不妨看看DriverManager类的源码,DriverManager是Java核心rt.jar包中的类,该类用来管理不同数据库的实现驱动即Driver,它们都实现了Java核心包中的java.sql.Driver接口,如mysql驱动包中的com.mysql.jdbc.Driver,这里主要看看如何加载外部实现类,在DriverManager初始化时会执行如下代码:
//DriverManager是Java核心包rt.jar的类
public class DriverManager {
//省略不必要的代码
static {
loadInitialDrivers();//执行该方法
println("JDBC DriverManager initialized");
}
//loadInitialDrivers方法
private static void loadInitialDrivers() {
sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//加载外部的Driver的实现类
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
//省略不必要的代码......
}
});
}
在DriverManager类初始化时执行了loadInitialDrivers()方法,在该方法中通过ServiceLoader.load(Driver.class);去加载外部实现的驱动类,ServiceLoader类会去读取mysql的jdbc.jar下META-INF文件的内容,如下所示:
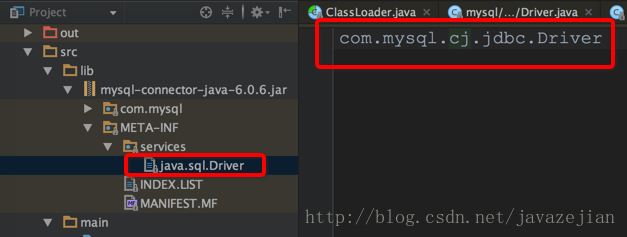
com.mysql.jdbc.Driver继承类如下:
public class Driver extends com.mysql.cj.jdbc.Driver {
public Driver() throws SQLException {
super();
}
static {
System.err.println("Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. "
+ "The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.");
}
}
从注释可以看出平常我们使用com.mysql.jdbc.Driver已被丢弃了,取而代之的是com.mysql.cj.jdbc.Driver,也就是说官方不再建议我们使用如下代码注册mysql驱动。
//不建议使用该方式注册驱动类
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/cm-storylocker?characterEncoding=UTF-8";
//通过java库获取数据库连接
Connection conn = java.sql.DriverManager.getConnection(url, "root", "root@555");
而是直接去掉注册步骤,如下即可
String url = "jdbc:mysql://localhost:3306/cm-storylocker?characterEncoding=UTF-8";
//通过java库获取数据库连接
Connection conn = java.sql.DriverManager.getConnection(url, "root", "root@555");
这样ServiceLoader会帮助我们处理一切,并最终通过load()方法加载,看看load()方法实现
public static <S> ServiceLoader<S> load(Class<S> service) {
//通过线程上下文类加载器加载
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
很明显了确实通过线程上下文类加载器加载的,实际上核心包的SPI类对外部实现类的加载都是基于线程上下文类加载器执行的,通过这种方式实现了Java核心代码内部去调用外部实现类。我们知道线程上下文类加载器默认情况下就是AppClassLoader,那为什么不直接通过getSystemClassLoader()获取类加载器来加载classpath路径下的类的呢?其实是可行的,但这种直接使用getSystemClassLoader()方法获取AppClassLoader加载类有一个缺点,那就是代码部署到不同服务时会出现问题,如把代码部署到Java Web应用服务或者EJB之类的服务将会出问题,因为这些服务使用的线程上下文类加载器并非AppClassLoader,而是Java Web应用服自家的类加载器,类加载器不同。所以我们应用该少用getSystemClassLoader()。总之不同的服务使用的可能默认ClassLoader是不同的,但使用线程上下文类加载器总能获取到与当前程序执行相同的ClassLoader,从而避免不必要的问题。ok~.关于线程上下文类加载器暂且聊到这,前面阐述的DriverManager类,大家可以自行看看源码,相信会有更多的体会,另外关于ServiceLoader本篇并没有过多的阐述,毕竟我们主题是类加载器,但ServiceLoader是个很不错的解耦机制,大家可以自行查阅其相关用法。
ok~,本篇到此告一段落,如有误处,欢迎留言,谢谢。
参考资料: http://blog.csdn.net/yangcheng33/article/details/52631940 http://ifeve.com/wp-content/uploads/2014/03/JSR133%E4%B8%AD%E6%96%87%E7%89%881.pdf 《深入理解JVM虚拟机》 《深入分析Java Web 技术内幕》