总结kafka的安装及使用方法
概念
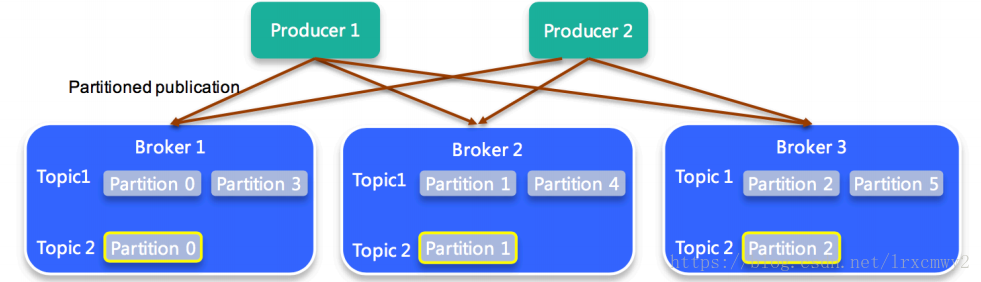
- broker
就是一个机器节点
- partition
Kafka的消息通过topic进行分类。topic可以被分为N个partition来存储消息(每个partition只会落在一个broker上,不会跨broker)。消息以追加的方式写入partition,然后以先入先出的顺序读取。
通过命令创建topic的时候可以设置-partitions 1参数来指定topic的消息分别存储到几个分区上,如果不指定,则使用broker配置config/server.properties中配置的num.partitions=1。topic的消息分发到partition上默认是通过hash来进行分区的,每个partition存储的数据是不同的。
partition磁盘文件的名称是logs目录下的以TOPIC_NAME-n命名的目录,例如demo-topic-0,目录下面是成对的xxx.index(记录消息偏移量等元数据),xxx.log(消息体本身),这一对文件称为segment file。

每个partition内部消息是有序的,但是多个partition无法保证消息的顺序。partition中的消息都有一个序号叫offset标记消息的位置。
topic的分区被分配在不同broker上,不同的broker上的partition组成topic的分区副本列表,其中有一个副本是leader,负责数据读写,其它分区作为备份。对于leader新写入的消息,consumer不能立即消费,必须等ISR(in-sync-replica)列表的所有partition都同步了(更新每个partition的HighWartermark之后)才可以消费,保证数据强一致性
每一个消息分区,只能被同组的一个消费者消费。
- producer
producer可以指定数据有几个分区(partition)、几个备份(broker)。producer只关联broker集群中的一个broker进行数据发送。消息的格式是key/value,key和value都可以为null,如果producer发送消息时未指定key,则消息随机选择partition存储,被指定了相同的key的消息会分配到相同的partition中。如果发送消息时明确指定了partition,那key会被忽略。
-
consumer
-
consumer group
每条消息只发送给分组中的一个consumer,不同的消费者分组消费自己特定的Topic下面的消息,互不干扰。
topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
安装
安装JDK8
基于centos7系统,已安装忽略此步骤
1.卸载centos原本自带的openjdk(直接使用openjdk也是可以的,只是缺少部分开发功能)
# 首先查找jdk安装包
rpm -qa | grep java
# 执行删除命令
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-xxxxxx
# 创建目录,用来放jdk安装文件
mkdir -p /usr/local/jdk
cd /usr/local/jdk
# 将tar.gz包放进来,然后执行解压
tar -zxvf jdk-8u221-linux-x64.tar.gz
cd jdk1.8.0_221
3.添加环境变量
vim /etc/profile
-------------------------------------------------------------------------------------------
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_221
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
-------------------------------------------------------------------------------------------
source /etc/profile
# 查看版本,确保安装成功
java -version
安装zookeeper
按照这个步骤安装zookeeper,安装好后启动zk服务器
安装kafka
下载地址,下载0.11.0.3版本的tgz包
mkdir /usr/local/kafka
cd /usr/local/kafka/
# 将tgz包放进来并解压
tar -zxvf kafka_2.11-0.11.0.3.tgz
# 修改配置文件
cd kafka_2.11-0.11.0.3/config/
vim server.properties
------------------------------------------------------
broker.id=0
listeners=PLAINTEXT://内网ip:9092
advertised.listeners=PLAINTEXT://服务器外网ip:9092
log.dirs=/usr/local/kafka/kafka_2.11-0.11.0.3/logs
zookeeper.connect=localhost:2181
------------------------------------------------------
# 配置环境变量
vim /etc/profile
------------------------------------------------------
export KAFKA_HOME=/usr/local/kafka/kafka_2.11-0.11.0.3
export PATH=$PATH:$KAFKA_HOME/bin
------------------------------------------------------
source /etc/profile
启动kafka
cd /usr/local/kafka/kafka_2.11-0.11.0.3
# 启动
sh ./bin/kafka-server-start.sh ./config/server.properties
# jps查看进程
# 停止
sh ./bin/kafka-server-stop.sh ./config/server.properties
# 查看zk里面broker的配置信息
zookeeper-shell.sh localhost:2181 <<< "get /brokers/ids/0"
# 创建一个测试topic
# replication-factor:消息保存在几个broker上,一般等于broker数量
# partitions:有几个分区,分区数量应该<=broker数量
# 也可以指定--replica-assignment 0:1,1:2,2:0(表示0、1、2三个分区,分别分布在3个broker上面)
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Hello-Kafka
# 查看topic列表
kafka-topics.sh --list --zookeeper localhost:2181
# 查看topic的分区信息
kafka-topics.sh --describe --zookeeper localhost:2181 --topic Hello-Kafka
# 修改topic的partition数量(分区数量只能增加不能减少)
# 修改partition也可以通过kafka-reassign-partitions.sh脚本指定json文件来修改:http://kafka.apache.org/documentation/#basic_ops_increase_replication_factor
kafka-topics.sh --zookeeper localhost:2181 --alter --topic Hello-Kafka --partitions 2
# 查看topic分区信息
kafka-topics.sh --zookeeper localhost:2181 --describe --topic Hello-Kafka
# 启动生产者客户端,发送消息
kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
# 启动消费者客户端,接收消息
kafka-console-consumer.sh --zookeeper localhost:2181 -topic Hello-Kafka
# 删除topic(配置中delete.topic.enable=true则)
kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-Kafka
彻底删除topic
# 1.停止producer以及consumer应用程序
# 2.server.properties设置
delete.topic.enable=true
# 3.执行删除topic命令
kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-Kafka
# 4.删除server.properties配置中`log.dirs`对应的目录
# 5.zk上执行删除命令
zkCli.sh -server localhost:2181
rmr /brokers/topics/TOPIC_NAME
rmr /admin/delete_topics/TOPIC_NAME
rmr /consumers/CONSUMER_GROUP
rmr /config/topics/TOPIC_NAME
# 6.查看topic列表
kafka-topics.sh --list --zookeeper localhost:2181
单机多broker集群(伪集群)
在一个机器上启动多个broker,只需要配置文件复制多个,broker.id、端口、日志目录配置修改一下,启动时指定不同的配置文件即可
/usr/local/kafka/kafka_2.11-0.11.0.3/config
cp server.properties server-1.properties
cp server.properties server-2.properties
vim server-1.properties
------------------------------------------------------
broker.id=1
port=9093
log.dirs=/usr/local/kafka/kafka_2.11-0.11.0.3/logs-1
------------------------------------------------------
vim server-2.properties
------------------------------------------------------
broker.id=2
port=9094
log.dirs=/usr/local/kafka/kafka_2.11-0.11.0.3/logs-2
------------------------------------------------------
# 启动3个broker
sh ./bin/kafka-server-start.sh ./config/server.properties
sh ./bin/kafka-server-start.sh ./config/server-1.properties
sh ./bin/kafka-server-start.sh ./config/server-2.properties
#如果想后台运行kafka,可以使用nohup命令(启动日志的目录logs、logs-1、logs-2需要手动创建一下)
nohup sh ./bin/kafka-server-start.sh ./config/server.properties >> ./logs/start.log 2>&1 &
nohup sh ./bin/kafka-server-start.sh ./config/server-1.properties >> ./logs-1/start.log 2>&1 &
nohup sh ./bin/kafka-server-start.sh ./config/server-2.properties >> ./logs-2/start.log 2>&1 &
测试集群
# 启动一个consumer
kafka-console-consumer.sh --zookeeper localhost:2181 -topic Hello-Kafka
# 启动3个producer发送消息到3个broker,会发现consumer可以收到所有的消息
kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
kafka-console-producer.sh --broker-list localhost:9093 --topic Hello-Kafka
kafka-console-producer.sh --broker-list localhost:9094 --topic Hello-Kafka
集群操作
# 创建topic,指定保存在3个broker上,这样在logs、logs-1、logs-2三个文件夹下面都会出现一个名称为multi-broker-topic-0的partition目录
sh ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic multi-broker-topic
# 查看topic信息
# 根据下面打印的信息可以知道,multi-broker-topic有一个分区,数据分布在3个broker上,这个分区编号是0(多个partition会有多行记录,编号递增),起作用的broker.id=2(leader编号),有3个副本(2,0,1开头的编号是起作用的broker.id)
sh ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic multi-broker-topic
----------------------------------------------------------------------------------------
Topic:multi-broker-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: multi-broker-topic Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
----------------------------------------------------------------------------------------
# 启动producer,发送消息
kafka-console-producer.sh --broker-list localhost:9092 --topic multi-broker-topic
# 启动consumer,接收消息
kafka-console-consumer.sh --zookeeper localhost:2181 -topic multi-broker-topic
kafka-topics.sh --describe命令查看的信息字段解释:
- PartitionCount:partition 个数
- ReplicationFactor:副本个数
- Partition:partition 编号,从 0 开始递增
- Leader:当前 partition 起作用的 broker.id
- Replicas: 当前副本数据所在的 broker.id,是一个列表,排在最前面的起作用
- Isr:当前 kakfa 集群中可用的 broker.id 列表
多机多broker集群
方法同单机多broker集群类似,需要注意的是broker.id区分开来,并且zk的地址配置成一样
集成springboot
常见mq对比
| Kafka | RabbitMQ | ActiveMQ | |
|---|---|---|---|
| 消息回溯 | 支持,无论是否被消费都会保留,可设置策略进行过滤删除(基于消息超时或消息大小) | 不支持,一旦被确认消费就会标记删除 | 不支持 |
| API完备性 | 高 | 高 | 中 |
| 单机吞吐量 | 十万级 | 万级 | 万级 |
| 首次部署难度 | 中 | 低 | 低 |
| 消息堆积 | 支持 | 支持(内存堆积达到特定阈值可能会影响性能) | 支持(有上线,当消息过期或存储设备溢出时,会终结它) |
| 消息持久化(数据持久化到硬盘) | 支持 | 支持 | 不支持 |
| 多语言支持 | 支持,Java优先 | 语言无关 | 支持,Java优先 |
| 消息优先级设置(某些消息被优先处理) | 不支持 | 支持 | 支持 |
| 消息延迟(消息被发送之后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费) | 不支持 | 支持 | 支持 |
| 消费模式(①推模式:由消息中间件主动地将消息推送给消费者;②拉模式:由消费者主动向消息中间件拉取消息) | 拉模式 | 推模式+拉模式 | 推模式+拉模式 |
| 消息追溯 | 不支持 | 支持(有插件,可进行界面管理) | 支持(可进行界面管理) |
| 常用场景 | 日志处理、大数据等 | 金融支持机构 | 降低服务之间的耦合 |
| 运维管理 | 有多种插件可进行监控,如Kafka Management | 有多种插件可进行监控,如rabbitmq_management(不利于做二次开发和维护) | 无 |
其它
zookeeper对kafka的作用
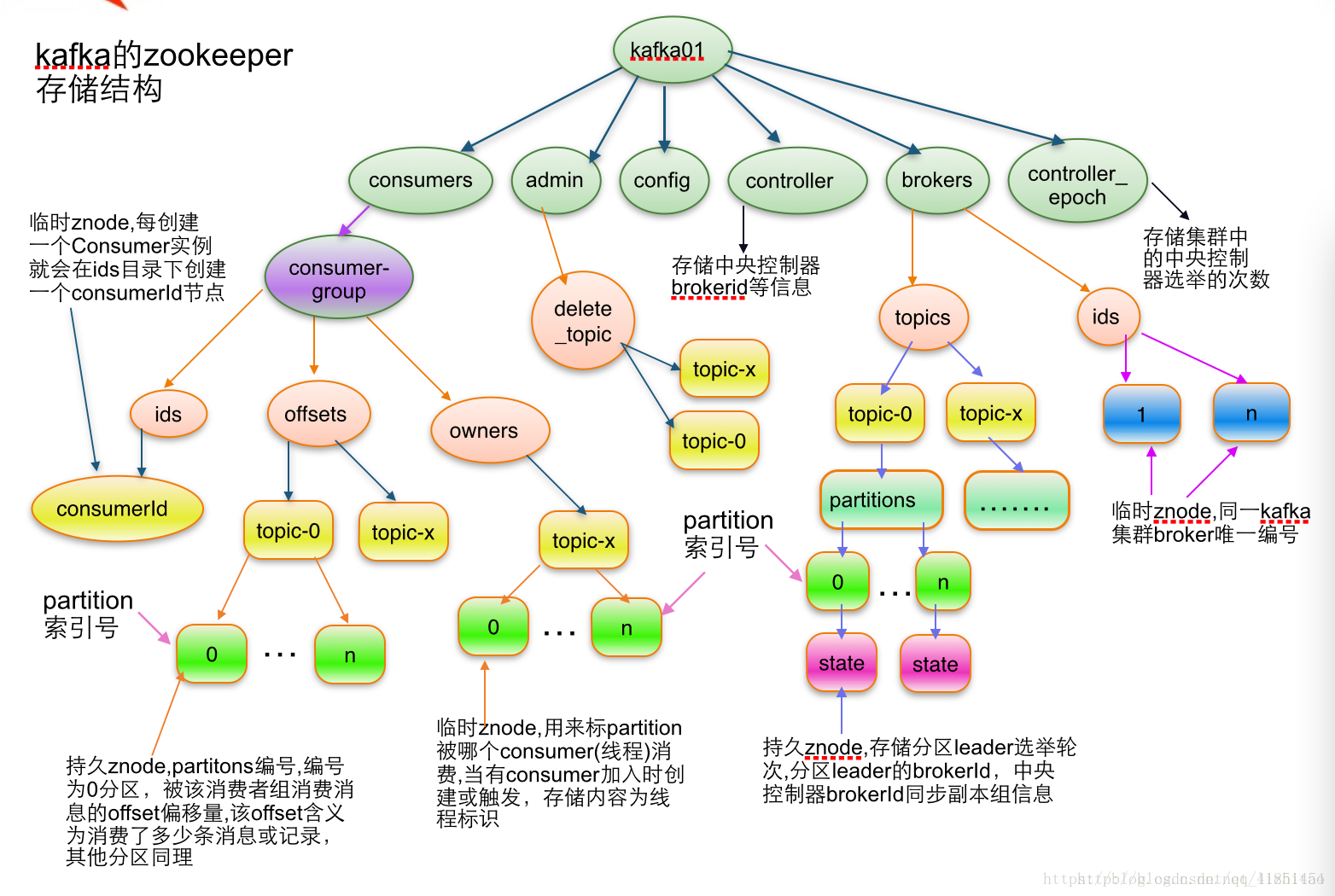
Broker注册:Broker在zookeeper中保存为一个临时节点,节点的路径是/brokers/ids/[brokerid],每个节点会保存对应broker的IP以及端口等信息.
Topic注册:在kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况都保存在zookeeper中,根节点路径为/brokers/topics,每个topic都会在topics下建立独立的子节点,每个topic节点下都会包含分区以及broker的对应信息
partition状态信息:/brokers/topics/[topic]/partitions/[0…N] 其中[0…N]表示partition索引号
Controller epoch:此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1;
Controller注册信息:存储center controller中央控制器所在kafka broker的信息
生产者负载均衡:当Broker启动时,会注册该Broker的信息,以及可订阅的topic信息。生产者通过注册在Broker以及Topic上的watcher动态的感知Broker以及Topic的分区情况,从而将Topic的分区动态的分配到broker上.
消费者:kafka有消费者分组的概念,每个分组中可以包含多个消费者,每条消息只会发给分组中的一个消费者,且每个分组之间是相互独立互不影响的。Consumer注册信息: 每个consumer都有一个唯一的ID(consumerId可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息./consumers/[groupId]/ids/[consumerIdString]是一个临时的znode,此节点的值为请看consumerIdString产生规则,即表示此consumer目前所消费的topic + partitions列表.
消费者与分区的对应关系:对于每个消费者分组,kafka都会为其分配一个全局唯一的Group ID,分组内的所有消费者会共享该ID,kafka还会为每个消费者分配一个consumer ID,通常采用hostname:uuid的形式。在kafka的设计中规定,对于topic的每个分区,最多只能被一个消费者进行消费,也就是消费者与分区的关系是一对多的关系。消费者与分区的关系也被存储在zookeeper中节点的路劲为 /consumers/[group_id]/owners/[topic]/[broker_id-partition_id],该节点的内容就是消费者的Consumer ID
消费者负载均衡:消费者服务启动时,会创建一个属于消费者节点的临时节点,节点的路径为 /consumers/[group_id]/ids/[consumer_id],该节点的内容是该消费者订阅的Topic信息。每个消费者会对/consumers/[group_id]/ids节点注册Watcher监听器,一旦消费者的数量增加或减少就会触发消费者的负载均衡。消费者还会对/brokers/ids/[brokerid]节点进行监听,如果发现服务器的Broker服务器列表发生变化,也会进行消费者的负载均衡
controller就是zk中的一个节点,谁创建成功了谁就成为控制器
集群中有一个 broker 会被选举为 Controller,负责管理集群 broker 的上下线,所 有 topic 的分区副本分配和 leader 选举等工作。partition的leader选举过程如下:

自定义分区规则partitioner.class
import java.util.List;
import java.util.Map;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.record.InvalidRecordException;
import org.apache.kafka.common.utils.Utils;
public class MyPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
//不允许key为null,如果key="*",投送到分区1,否则取模确定分区
if(keyBytes == null) {
throw new InvalidRecordException("key cannot be null");
}
if(((String)key).equals("*")) {
return 1;
}
//如果消息的key值不为*,那么使用hash值取模,确定分区。
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {
}
}
在producer端的配置中添加这个自定义的partitioner即可
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartitioner.class.getCanonicalName());
消息的顺序
- 单partition
如果消息被分布到多个partition中是无法保证全局有序的,producer在发送消息到broker的时候可以精确指定消息发送到哪个partition,通过发送到指定的单个partition来保证消息顺序,或者一个topic仅创建一个partition,全部消息都存储到里面,也可以保证有序。
如果设置了retry,消息1和消息2顺序发送给broker,但是这个时候消息1处理失败,消息2处理成功,消息1又重试了一次并且这一次成功了,这两条消息顺序就被打乱。为了保证顺序写,在producer应用中需要设置以下参数:
# 设置此值是1表示kafka broker在响应请求之前producer不能再向同一个broker发送请求,默认值为5
max.in.flight.requests.per.connection=1
# 或者开启幂等
enable.idempotence=true
- 多partition
producer在发送消息到broker的时候可以指定key(一般是消息payload本身的某一个属性字段),具有相同key的消息会被分配到相同的partition中,这样订阅了该topic的consumer在消费这个partition中的消息时就能保证顺序,默认是通过Hash(key)%partitionNb算法来指定partition的。但有个问题是,如果partition增加了,但是key并没有变化,那消息会被存储到不同的partition了。
同样要设置producer的参数。
- 总结
其实上面的两种情况总结下来都是通过把需要保证顺序的消息投递到单一partition
-
如果一个topic下的所有消息都需要保证全局有序,那这个topic只能创建单一的partition来存储
-
如果一个topic下的消息只是按照某一个维度需要保证有序,那以这个维度作为key,消息都存储到单独的partition,但是topic可以有多个partition来存储其他消息
重新消费消息
在zookeeper中记录了consumer消费topic的最新offset值:/consumers/{group.id}/offsets/{topic}/{partition.id}
# 查看topic列表
kafka-topics.sh --list -zookeeper localhost:2181
# 查看某个topic的分区情况
kafka-topics.sh --describe -zookeeper localhost:2181 --topic topic1
# 查看某个topic的offset情况,当前消费offset,最大offset,积压数,owner
kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group myGroupId --topic topic1 --zookeeper localhost:2181
# 查看最小offset,结果topic1:0:0 中间的0代表partition编号,最后的0代表最小offset
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.237.128:9092 --topic topic1 --time -2
# 查看最大offset,结果topic1:0:12345 中间的0代表partition编号,12345代表最大offset
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.237.128:9092 --topic topic1 --time -1
# 通过zookeeper修改offset值,修改的时候需要停掉订阅的consumer,否则consumer会不断更新这个值
ziCli.sh -server localhost:2181
set /consumers/[group_id]/offsets/[topic]/0 1288
# 【注】新版本的consumer已经不依赖zookeeper,这个节点是空的,新版本的consumer的offset存储在一个单独的topic(__consumer_offsets)里面
# 新版本可以使用这个工具来修改offset(只有consumer停止才能执行)
# 参考:https://cwiki.apache.org/confluence/display/KAFKA/KIP-122%3A+Add+Reset+Consumer+Group+Offsets+tooling
kafka-consumer-groups.sh --bootstrap-server 192.168.237.128:9092 --group myGroupId --topic topic1 --reset-offsets --to-earliest
kafka-run-class.sh kafka.tools.UpdateOffsetsInZK earliest config/consumer.properties topic1
事务
Kafka的事务不同于Rocketmq,Rocketmq是保障本地事务(比如数据库)与mq消息发送的事务一致性,Kafka的事务主要是保障一次发送多条消息的事务一致性(要么同时成功要么同时失败)。
延时消息
原生Kafka默认是不支持延时消息的,需要开发者自己实现一层代理服务,比如发送端将消息发送到延时Topic,代理服务消费延时Topic的消息然后转存起来,代理服务通过一定的算法,计算延时消息所附带的延时时间是否到达,然后将延时消息取出来并发送到实际的Topic里面,消费端从实际的Topic里面进行消费。
ISR机制(broker保证消息不丢失)
问题
如何保证kafka消息不丢失
producer端
使用带回调的方法send(msg, callback),发送失败时进行重试,收到broker的ack时才算发送成功
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
//*******重点*****************
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
broker端配置

consumer端
关闭自动提交,处理完成之后再进行提交
出现问题之后需要应用自行重试消费
参考
***理解 Kafka 中的 Topic 和 Partition
How to choose the number of topics/partitions in a Kafka cluster?